


Web scraping has quietly become one of the most useful research skills an institution can build. Universities track tuition trends, libraries monitor open-access publishing, and research teams assemble public datasets that would take months to gather by hand. It is also legal in most cases — it is simply the automated collection of information that is already public.
The catch is that the line between “perfectly legal” and “you have just been sued” can be thin. It depends on what you collect, how you collect it, and where that data ends up. With automated traffic now making up close to half of all activity online (Imperva’s 2024 Bad Bot Report puts non-human traffic at roughly 50%), website owners and regulators are paying closer attention than ever.
This guide maps the legal landscape for educational organizations: the rules that matter, the cases that shaped them, and a practical framework for keeping your data collection defensible.
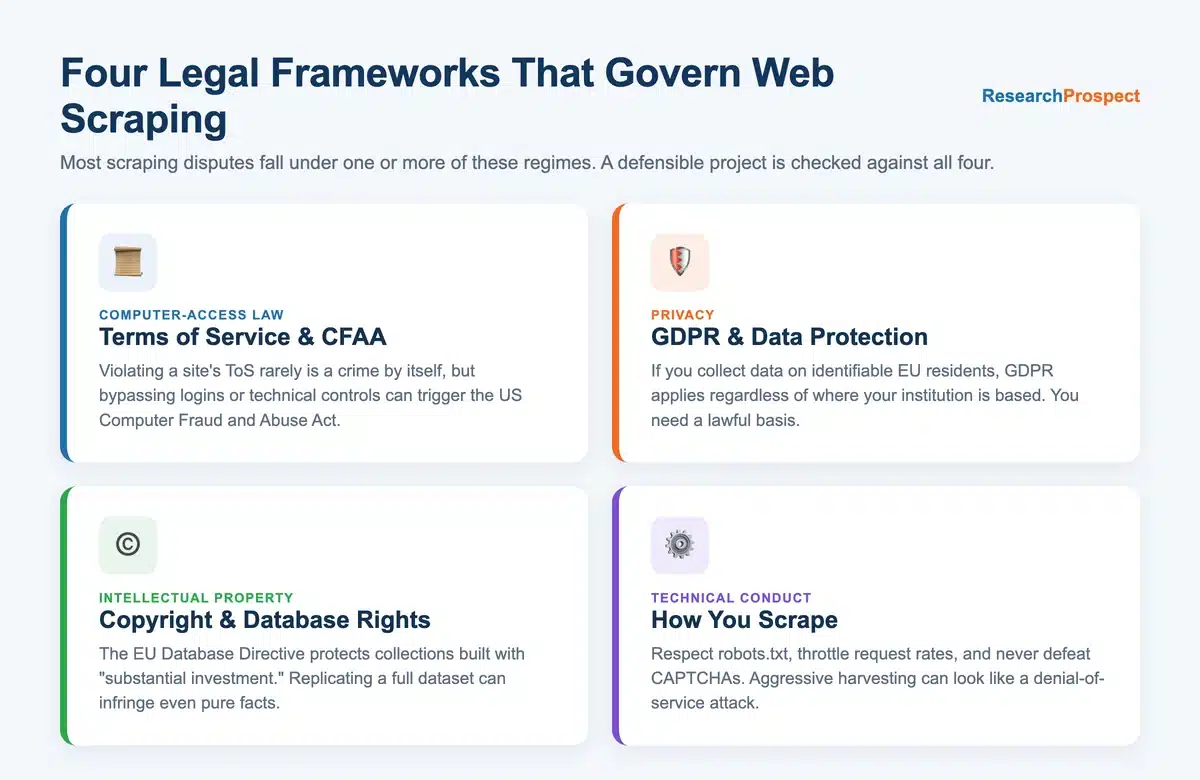
Web Scraping Is Legal — But Context Decides Everything
Let us state it plainly: web scraping is not illegal. Courts in the United States and Europe have repeatedly accepted that collecting publicly available information is legitimate. What turns a routine research task into a legal problem is context — the type of data, the method of access, and the people that data describes.
When you scrape for competitive analysis or academic work, you do not need to be a lawyer, but you do need a rough map of where the risks sit. The sections below are that map. For researchers, scraping is often just a faster route to the kind of evidence you would otherwise gather through traditional data collection methods or secondary research.
What Terms of Service Actually Mean
Every website publishes a Terms of Service (ToS) document, and almost nobody reads it. When scraping is involved, those terms are the first thing that surfaces if a dispute arises. Some sites explicitly prohibit automated access; others stay deliberately vague.
Here is the nuance most people miss: breaching a site’s ToS does not automatically make you legally liable in most jurisdictions. It can, however, be used as evidence of bad faith. In the United States, the question has been tested under the Computer Fraud and Abuse Act (CFAA), and the results have not always favoured scrapers.
The landmark hiQ Labs v. LinkedIn case ran through the courts for six years. The Ninth Circuit accepted that scraping publicly accessible profiles did not, by itself, violate the CFAA. Yet the dispute ended in December 2022 with a consent judgment of US $500,000 against hiQ — partly because hiQ had used fake accounts to reach password-protected pages. The lesson is sharp: public data is defensible, but the moment you log in or fake your way past a barrier, you are in a different legal universe.
Practical rule: if you must sign in to see the data, treat the project as high-risk. If you are reading a public product page, you are on far safer ground.
Public vs. Private Data: A Simple Rule for a Complicated Topic
This is where many teams go wrong. They assume “publicly available” means “free to use.” Sometimes that is true; often it is not. The distinction interacts with copyright and privacy law rather than overriding them. The table below shows how the same activity shifts in risk depending on the data involved.
| Scenario | Typical Risk | Primary Law in Play |
|---|---|---|
| Public page, no login required | Low to moderate | Copyright & database rights |
| Data behind a login or paywall | High | CFAA / contract |
| Personal data of EU residents | High | GDPR |
| Replicating an entire third-party database | High | Database rights |
None of these factors is decisive on its own. A court — or a regulator — looks at the whole picture.
GDPR and Data Protection: The Rule Everyone Talks About
Suppose you want to collect information about individuals — names, emails, behaviour, location history. If any of those people are based in the EU, the General Data Protection Regulation (GDPR) applies to you, regardless of where your institution is registered.
GDPR enforcement is not theoretical. Cumulative fines across Europe passed €5.8 billion by early 2025 (CMS GDPR Enforcement Tracker), with around €1.2 billion issued in 2024 alone. Before you scale any collection of personal data, you should be able to answer four questions:
- Are you collecting data about identifiable individuals?
- Do you have a purpose that qualifies as a legitimate interest?
- Have you carried out a proper balancing test?
- Can you respond to a data-subject access request?
If the honest answer to most of these is “no” or “I’m not sure,” that is a problem to solve before, not after, you begin.
Copyright and Database Rights
People usually think of copyright in terms of articles, images, and creative work — not structured data. But in the EU, databases can carry their own legal protection, separate from copyright. The EU Database Directive protects collections where there has been “substantial investment” in obtaining, verifying, or presenting the contents.
Scraping a competitor’s entire product catalogue could qualify. Repeatedly pulling data to rebuild a database someone else assembled is exactly what the directive was written to cover. In the US, pure facts are not copyrightable — but the selection, arrangement, and presentation of data can be, and reproducing enough of it puts you on contested ground. Fair use offers some protection for transformative, research, or commentary purposes, but it is a defence you argue in court, not a right you assume in advance.
How You Scrape Matters as Much as What You Scrape
Technical conduct has legal consequences. Sending thousands of requests per second can be characterised as a denial-of-service attack, even if that was never your intent. Ignoring robots.txt will not get you sued on its own, but courts have read it as a signal of intent. Defeating CAPTCHAs or other access controls is explicitly risky under the CFAA and comparable laws elsewhere.
This is partly why responsible infrastructure matters. Using a reliable web scraping proxy service such as Geonix does more than solve the technical problems of IP rotation and rate limiting — it keeps your collection measured and non-evasive, which is exactly the behaviour a court wants to see. The difference between ethical research methodology and aggressive data harvesting often comes down to intent and proportionality, and how clearly you can demonstrate both.
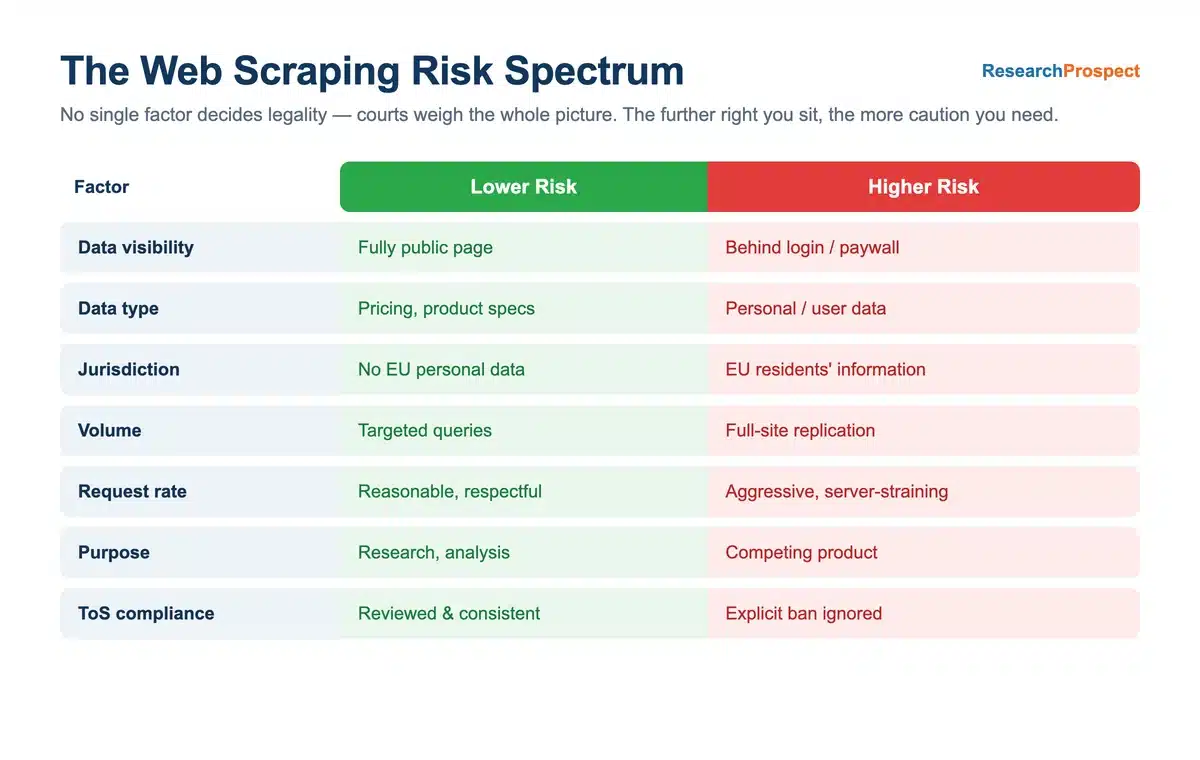
What “Permissible” Data Extraction Looks Like
There is no universal checklist, but defensible projects share a recognisable profile. The spectrum below summarises the factors that pull a project toward lower or higher risk — check a new project against each one before you start collecting.
A Quick Decision Framework
When you scope a new project, walk through these questions in order. If you reach the bottom without hitting a red flag, your collection is likely defensible.

Academic Citation and Research Use
Research use earns more latitude in almost every framework. Fair use is easier to argue in the US when the purpose is non-commercial research, and GDPR contains specific exemptions for research. But “I’m doing research” is not a magic phrase — institutional review processes exist for a reason, and you still need to defend your methodology.
If you work in an academic context, document everything: why the scraping was necessary, what controls you applied, and how the data will be used. That paper trail is worth having if anyone ever asks. If you are citing scraped data in a dissertation or paper, our dissertation research support and free academic integrity tools can help you keep the write-up clean. For the mechanics, see our guides on how to cite sources properly and avoiding plagiarism in your work.
Final Thoughts
Looked at closely, web scraping is a genuinely complex legal subject. The law varies from country to country, and court cases sometimes end unpredictably. The one thing we can say with confidence is that collecting reasonable amounts of publicly available information is justified. Problems arise when you gather personal data carelessly or ignore explicit rules.
So plan deliberately: use reputable proxies, respect rate limits, review the Terms of Service before you start, and check the current law in the country where you operate. For a large or sensitive project, a short conversation with a lawyer is cheap insurance.
Frequently Asked Questions
Yes. Web scraping is legal when an institution collects publicly available data and respects the website’s Terms of Service, copyright and database rights, and privacy laws such as GDPR. The risk rises sharply once you access data behind a login or gather personal information without a lawful basis.
Publicly accessible, non-personal information is the safest category, for example research publications, market and pricing trends, academic statistics, and open educational resources. Avoid scraping personal data, login-protected content, or entire third-party databases without permission.
Review the site’s Terms of Service, respect robots.txt, throttle your request rate, avoid collecting personal data without consent or another lawful basis, and document your methodology. Using reputable proxy infrastructure and keeping volumes proportional also demonstrates good faith.
Done responsibly, scraping lets institutions gather large research datasets quickly, track educational and market trends, benchmark against peers, and support data-driven decisions, work that would be impractical to do by hand.


