Disclaimer: This is not a sample of our professional work. The paper has been produced by a student. You can view samples of our work here. Opinions, suggestions, recommendations and results in this piece are those of the author and should not be taken as our company views.
Type of Academic Paper – Essay
Academic Subject – Statistics
Word Count – 2000 words
In this document, the data analysis has been done to assess advanced statistical analysis. The first part consists of the analysis of variance, also known as ANOVA, where the attractiveness ratings are considered the discrete predictor or independent variable. The second part consists of a regression model where the two independent variables are attractiveness as a continuous predictor and attractiveness ratings as a discrete predictor to get attractiveness level. The third part consists of the linear mixed model where the same continuous and discrete predictors are used to form mixed model with fixed effect and mixed model with random effect. A random intercept was also predicted in the analysis for both raters (female participants) and rated (male confederates). The document also contains a Bayesian analysis and power analysis. In the end, the conclusion of the whole discussion is present.
The following analysis is conducted with regard to the rating condition as the discrete predictor. The situation was that a group of researchers was trying to determine how likely people agree to date unattractive people out of pity. The female participants in this study were the raters, whereas 20 males were used as rated. The rating was done on the basis of how likely are females are going to date unattractive people. Analysis of variance or more commonly called ANOVA, was used for assessing the results of this study.
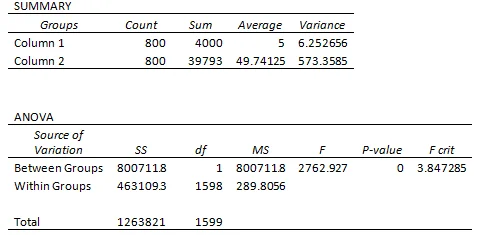
Based on the application of ANOVA, it was found that the rating condition used as a discrete predictor was found to be significant. The table below shows the output of ANOVA obtained from Excel. The first chart of summary shows variance, and the next table below shows ANOVA. The value of F-statistic in the given table is greater than the critical value of F-statistic, which means that the hypothesis of the study that females date unattractive people out of pity was rejected by the null hypothesis. The P-value is 0, which means that the results are highly significant, and the females mostly date males out of pity if they are unattractive. Furthermore, the variance shows that the values deviate from the mean. The P-value also shows that the ANOVA shows significant results of the data. In addition to this, it was also found from the below table that the research conducted by the researchers was validated because the results are significant. However, if the results were not significant and the value of P had been more than 0.05 so, the research was declared to be not successful.
The table below also shows that ANOVA is a statistical technique that helps understand the variance between groups of means. The ANOVA also shows the variance within the groups and between the groups taken under consideration for analysis. There are two types of ANOVA, but the researcher had conducted one-way ANOVA only to obtain results quickly for the following study. The rating condition was taken as the discrete predictor because the researcher had used attractiveness as one variable. The other was rating done to the number of dates females go if they males are unattractive. Moreover, the attractiveness of the male gender was not considered as the dependent variable because it depends on the choice of the females to select males.

Regression analysis is defined as the statistical method used for determining the relationship between independent and dependent variables. The purpose of using regression analysis is to validate whether any association exist between two variables. SPSS and Microsoft Excel are used to find out the relationship through regression analysis.
The second part of the situation was to conduct a standard multiple regression model with rating conditions. SPSS was used to obtain results for multiple regressions. Three tables were obtained: model summary, coefficient and ANOVA. The first table above of the Model summary shows that the R-value was 46.4% and R-square was 21.5%; however, the significant F-change was 0.000. The R and R square values show weak results, which mean that in comparison with the analysis of variance conducted in the earlier section, the R-value and r square are weak, which do not validate the results. Furthermore, the results in the above table also show that the rating condition cannot be validated accurately as the model is not very fit for analysis.
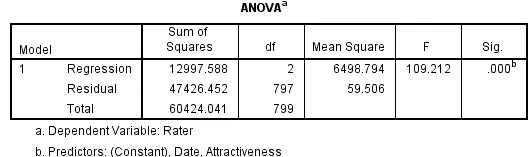
The second table of regression analysis is ANOVA. It shows the variance between groups of means. The most important value taken under consideration in the above table is the significance value. The table of ANOVA shows that the value of sig or the P-value was 0.000, which is less than the alpha value of 0.05; hence it validates significant results. Attractiveness was taken in this study as the independent variable, and rater was used as the dependent variable. The results show that the F-statistic is high, and the sig-value is also 0.000, which means that rater and attractiveness have a relationship.
The third table of regression analysis was coefficients. It shows the significant value of the variables taken for analysis. The significance value was 0.000, which shows that the results are substantial and have a strong association. Rater and attractiveness have a relationship because the beauty of females increases if the male is not attractive and go on a date for pity. The table of coefficients of determination is very important for regression analysis as it helps analyse and understand the increase in the dependent variable with one unit increase in the independent variable.
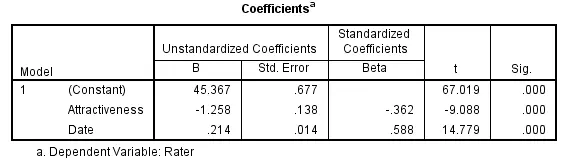
The third table of regression analysis was coefficients. It shows the significant value of the variables taken for analysis. The significance value was 0.000, which shows that the results are significant and have a strong association. Rater and attractiveness have a relationship because the attractiveness of females increases if the male is not attractive and they go on a date for pity. The table of coefficients of determination is very important for regression analysis as it helps analyse and understand the increase in the dependent variable with one unit increase in the independent variable.

The second test applied in this study was the Bayes factor for the One-Sample t-test. The table above shows that the sample size was 800, the standard deviation and mean along with the significant value. It also assumes that the data or the observations made are all normally distributed. The considerable value is 0.000, which is less than 0.005, meaning that the observations made are all normally distributed and are significant. The Bayes factor in the table above is also 0.000 for rater, rated, attractiveness and the date. Hence, people are likely to agree that dating unattractive people out of pity is positive and significant.
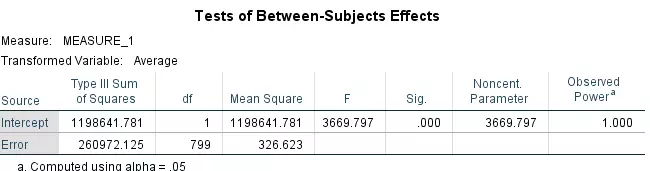
The tests of analysis used for this study was tests between-subject effects to understand the power value. The table shows that the overall observed power was 1.000, whereas the significant value, in this case, was also 0.000. It is the power of the applied tests derived based on the size of the total data and observations. The main purpose of using these tests is not to focus on the power but the size of the data used.
Orders completed by our expert writers are
A mixed model helps analyse a variety and range of correlation patterns. There are both effects incorporated in the mixed model that are random and fixed. A linear mixed model is one dimensional and has a degree equal to one. It is nothing but an extension to the general linear models. If the values of the variables of the interest are present in the data set, then those are called fixed effects, whereas; if the values are random in the given dataset, then those are called random effects.
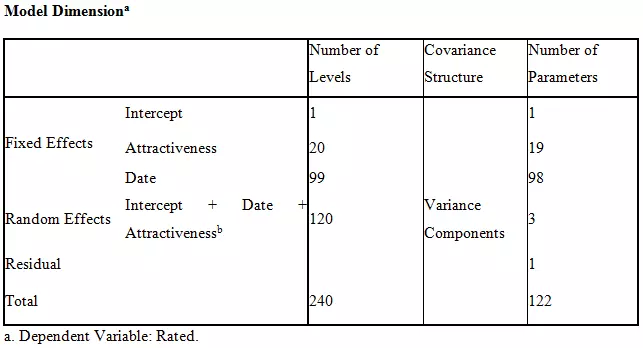
The table mentioned above shows a mixed model with random and fixed effects, also known as model dimension. The dependent variable is rated (male confederates) who were rated by the female participants based on their level of attractiveness. The total term in the model shows the overall complexity of the model, especially in the column of several parameters. The column of the number of levels shows how many lines are dedicated to an explanatory variable that can easily be seen above. The residual number of parameters shows how much data was out of reach for estimated parameters and was completely blank. The intercept value shows the number of random effects. Here in the model, we have one random effect that can be seen in the table.
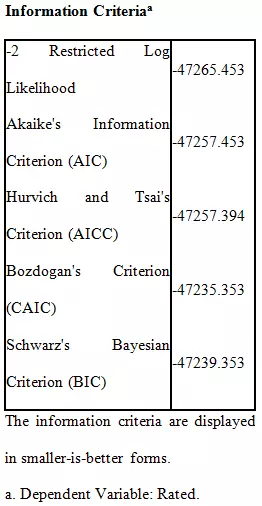
The above table shows the information criteria of the linear mixed model. The focus is more on Schwarz’s Bayesian Criterion (BIC) that is quite small, and negative means that the model is good. The small value of AIC or BIC indicates that the model is more adequate. These information criteria are generally taken as a universal parameter of the adequacy of the model. This shows that the model is highly significant based on the dependent variables as the male confederates (rated variable). It depicts that attractiveness does have an impact on the female participants to date that person.
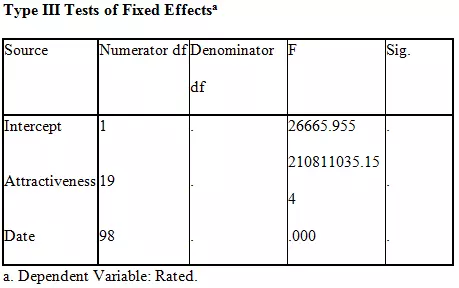
The table shows a test for the fixed effects model, similar to the ANOVA table. The f value indicates that the model is significant where the random variable is taken as rated male confederates on an average.
On the basis of rater that are the female participants who rated the male on their level of attractiveness and likelihood to date them, following results were obtained:
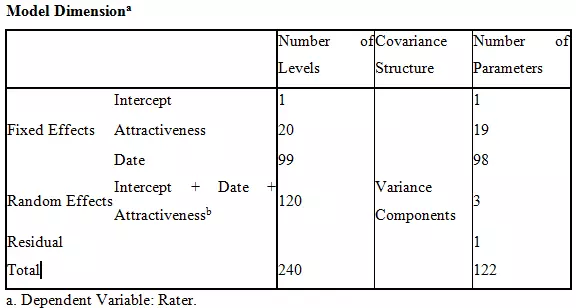
Here, with respect to the rater variable as a dependent, the results are similar to the rated variable. The complexity of the model is quite high. The residual number of parameters is also one, which means that only one estimated parameter was beyond the range during the analysis. However, the taken dependent variable is the female participants who rated male colleagues.
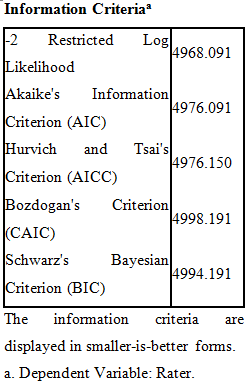
Schwarz’s Bayesian Criterion (BIC) is quite high, which means that the model does not seem to be effective with respect to the rater dependent variable. The lower the Bayesian Information Criterion (BIC) value, the better the model is and similar to Akaike’s Information Criteria (AIC). The value of AIC is also not appealing so. This model is not a good fit for the attractiveness of male confederates concerning the data of ratings provided by the female participants on beauty. So, this model does not seem to be adequate.
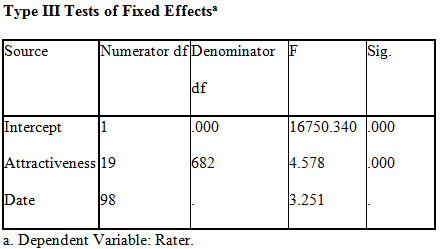
In the analysis aggregately, various tests are being run, and multiple aspects are tested. It can be concluded that the linear regression model seems to be more accurate. Based on R-squared, the linear regression analysis concerning rated (the male confederates) appears to be more precise, concluding that the model is the best fit. Based on the mixed model, the model does not appear to be significant enough, but the model with a dependent variable as rated (male confederates) is substantial based on the lowest BIC value. The two models validated that the results concerning rated male confederates as the dependent variable are significant. The attractiveness of male confederates matters for the female participants to date their male colleagues or allies.
If you are the original writer of this essay and no longer wish to have the essay published on the www.ResearchProspect.com then please:
Tips for writing an excellent undergraduate essay:

All work is written by human writers. 100% AI free, guaranteed.

100% money back guarantee if you find plagiarism in our work.
COMPANY DETAILS



